How Does Your Voice Agent Know When It Mishears?
The fallibility of ASR confidence as a predictor of correctness.
The question
Voice agents are being deployed in increasingly high-stakes scenarios. We’re still in the early phases of the rollout. Today, a critical failure often means lost revenues. But a future where we rely on voice agents for safety-critical roles means that effective evaluation becomes essential for health and safety.
Imagine a medical scribe agent capturing the wrong medication name, an emergency dispatch agent capturing the wrong street address, or an air traffic control agent hearing the wrong flight number. These errors can result in harm to humans.
The examples above are all instances of the critical failure mode of mishearing key information. When the agent can’t reliably hear, it should escalate to a human. So the practical question, for anyone building one of these agents, is: how does it know?
The trouble with ASR Confidence
To clarify the setup here, the Whisper ASR model is not the same as the ‘agent’. Whisper takes the audio and returns text plus a confidence number. The agent does everything else: it takes Whisper’s text and confidence and chooses whether to commit the value, ask the speaker to repeat, or escalate to a human.
Most ASR models expose some kind of confidence number. The Whisper family of models, for example, exposes the per-token probabilities of the transcript it decoded. A natural way to represent its overall confidence in its transcription then is exp(avg_logprob), the geometric mean of the per-token probabilities.1 You can then wire that into an escalation policy: above some threshold, commit; below another, escalate; in between, ask the person to repeat.
But ASR confidence isn’t the same as correctness. It scores how confidently Whisper produced the tokens it chose, not whether those tokens are true. In some scenarios confidence is a good proxy for correctness. On clean-ish audio a dip in confidence might correspond to a mistaken letter. But on degraded audio ASR confidence decorrelates from correctness. And the agent can’t tell from ASR confidence which regime it’s in. For example, when given severely degraded audio, Whisper often hallucinates a transcription with high confidence (see the top image). So is the model confident because it hallucinated on degraded audio or because it’s actually correct?
We’ll look at how Whisper behaves on my ID capture benchmark to get a sense for the failure modes of ASR confidence as a predictor of speech-to-text transcription correctness.
The benchmark
The benchmark simulates the challenge of capturing essential info over degraded audio channels. I generated 100 test cases consisting of 200 audio fixtures (the fixed, pre-generated clips the benchmark feeds the agent, two attempts per case) using the ElevenLabs TTS API. Each fixture is a short spoken identifier, e.g. “S as in sierra, X-ray, one, one, eight, five” (so the canonical ground truth here would be: SX1185). The cases span five buckets of increasingly degraded audio.
The key feature to understand about these buckets is that the ‘severe’ bucket is engineered so that a human cannot possibly make out the ID. Every other bucket (clean, light, moderate, heavy) is degraded but still perfectly intelligible to a human. The severe fixtures are adversarial examples that evaluate whether the agent gives up and escalates when the audio really can’t be heard, rather than confidently making something up.
| Bucket | n | Distortion |
|---|---|---|
| clean | 15 | none |
| light | 15 | mild noise OR phone bandpass alone |
| moderate | 20 | phone bandpass + 10 dB SNR noise |
| heavy | 25 | phone bandpass + 5 dB SNR + light dropout |
| severe | 25 | phone bandpass + −12 dB SNR + 250 ms dropout @ 55% per-window |
Simulating phone distortion
The deterministic degradation pipeline simulates the sort of distortion artifacts that you hear on a phone call (you might say it’s a bit phone-y2): a 300–3400 Hz bandpass filter (the standard phone band), a μ-law codec roundtrip (the standard phone codec. A codec is the scheme that compresses audio for transmission and decompresses it on the other end), additive white noise at a configurable SNR (signal-to-noise ratio), and packet dropout where 250 ms windows are silenced at a configurable probability. The severe bucket layers all four and pushes things beyond human-level recoverability. Also, the catalog is seeded, so rerunning the generator produces byte-identical fixtures.
The agent loop and what we measure
For each case, the agent being tested receives the audio file and chooses one of three actions: commit a transcription, ask the other person to repeat (one retry allowed), or escalate to a human. To recap, on the cases where the audio is actually unintelligible, the right behavior is to escalate. If your agent is recording something like a medication, an emergency address, or a patient identifier, you want it to fail loudly.
The benchmark then grades the agent on capture accuracy as well as escalation performance, which is derived from the four standard classifier outcomes we define for our setup as follows:
- True positive (TP): a genuinely impossible (severe) clip that the agent escalated.
- True negative (TN): a genuinely tractable (non-severe) clip that the agent did not escalate.
- False positive (FP): a tractable clip the agent escalated anyway. It mistook a hearable clip for an impossible one.
- False negative (FN): an impossible clip the agent committed on. It mistook an unhearable clip for a tractable one.
From these we get recall, precision, and F1:
- Recall = TP / (TP + FN). Of the genuinely impossible (severe) cases, what fraction did the agent correctly escalate? Low recall means it confidently committed answers it had no business committing.
- Precision = TP / (TP + FP). Of all the cases the agent escalated, what fraction were genuinely impossible? Low precision means it cried wolf, dumping easy cases on a human.
- F1 their harmonic mean:
2 · precision · recall / (precision + recall). It’s a single number that’s only high when both precision and recall are high.
Note my unusual choice to define the positive class as the severe (impossible) bucket. Our escalation metrics here are thus in terms of whether the agent correctly classified a fixture as impossible. Another option would have been to define the positive class as the case when the agent misheard. I wanted to investigate the former definition because it more directly encodes this question of whether the agent is able to tell when the audio is obviously impossible, which is this commonsense ability for any human agent, and something we’d reasonably want from our AI.
To exercise the benchmark I built a simple deterministic agent that wraps a Whisper ASR model.3 The agent transcribes the audio, runs a deliberately simple parser over the transcript, and decides whether to escalate based on Whisper’s confidence. My agent’s austere escalation policy looks like this:
# voice_agent_eval/whisper_agent.py — the policy gate
def decide(asr_text: str, confidence: float) -> Action:
parsed = parse_id_shape(asr_text) # uppercase, strip, normalize
if parsed is None or confidence < ESCALATE_BELOW:
return Escalate()
if confidence < CONFIRM_BELOW:
return AskForRepeat()
return Commit(parsed)Simplifying Assumptions Focus The Benchmark
What we’re doing here is taking a surgical approach to checking a single domain-specific high-stakes failure mode. By discarding extraneous details we’re able to better isolate what we’re interested in.
Some of the complexities this setup removes:
- Both the benchmark’s interlocutor and the agent I built to exercise the benchmark forego an actual LLM for the ‘brain’ of the agent. They’re fully deterministic. Only the ASR model introduces uncertainty.
- We also forego any sequence of realistic conversational turns preceding the ID transcription challenge.
- The benchmark provides the agent very limited options: submit a transcript capture, escalate to a human, or ask to repeat the audio file.
- Importantly, the setup completely ignores many of the essential challenges of the voice agent domain: turn-taking, barge-ins, end-pointing, latency, etc. In fact, the benchmark is not even real-time. It’s turn-based, with an optional HTTP-based FastAPI server. These real-time issues are not germane to the question our benchmark is asking.
It’s also worth pointing out that the purpose of this benchmark is not to assess frontier capabilities, but rather to catch regressions (by which I mean performance dips, not to be confused with linear regressions). The current generation of agents can easily perform well on it already.
The regression
I ran my agent on the benchmark with four different Whisper ASR model sizes. When I initially swapped them in without tuning the escalation policy threshold, capture rate increased monotonically (good!), but so did the wrong-commit rate on the ~impossible ‘severe’ bucket, which rose from 0% in Whisper tiny.en up to 64% in Whisper large-v3 😬.
These metrics are defined as follows:
- Capture rate: the share of all cases where the agent committed a transcription and got it right. Higher is better.
- Wrong-commit rate: the share of cases where the agent committed an answer that was wrong. It confidently handed back a bad ID instead of escalating or asking for a repeat. Higher is worse. On a severe case, any commit is a wrong commit, since the audio was unrecoverable.

All the ways you could have missed this regression
Let’s walk through the layers of how you might miss it in practice:
- Having an agent that has no way of knowing how confident it is in its transcription (from my personal conversations, this seems to remain common as of this writing). In this case it’s a moot point and you’ll find out from your customers.
- Not specifically evaluating the failure mode you’re interested in. If it would be really bad for your voice agent to fail in production by mishearing certain info and not escalating, then your eval suite should test for that. It would be easy to gloss over in a broad end-to-end evaluation.
- Only looking at ID capture accuracy. “Look! Accuracy increases with a bigger model.” Ignoring the escalation behavior would miss the bug.
- Not including adversarial examples in the benchmark If you only tested clean samples you also would miss it.
- Only looking at the aggregate wrong-commit rate. Check out the amber line in the chart above. Overall the escalation behavior doesn’t look so bad. But when you look specifically at the impossible cases, it’s clear that the large model has totally lost the plot. My benchmark happens to be only ~25% severe, so large’s catastrophic 64% severe rate gets diluted down to a tolerable-looking ~24% overall. But that mix is arbitrary. If your production audio is the kind where a large fraction of calls are in severe-grade conditions (a noisy ER, a bad cell connection, a loud factory floor), then you’ll care a lot more about the severe-bucket wrong-commit rate because that’s the day-to-day distribution you’re dealing with.
- Calibrating the model’s escalation policy to this benchmark. The distribution of severe audio samples is arbitrary and has no relation to any actual production situation. Below I do an F1 sweep to find the ‘optimal’ for each model. But the calibration settings only work for this distribution of fixtures.
The band-aid: Threshold Recalibration
Once I caught the bug I found new thresholds for each model by doing a threshold sweep and finding the optimal F1 score for each model (since presumably we want a good balance of recall and precision). That produced the following nice-looking chart:

Post-calibration, better models indeed performed better on both capture accuracy and escalation policy as you’d hope and expect. Check out that Pareto frontier!

Note well that the calibration is only ever as meaningful as the distribution you calibrate it on. I calibrated against my benchmark’s arbitrary mix of buckets (~25% severe), which bears no particular relationship to your production audio. But if you’re actually deploying one of these systems, hopefully you’re sitting on logged audio recordings paired with the true, eventually-verified ID for each one. So you would ideally construct a dataset from your actual production data (or at least with a similar distribution) and sweep the threshold to find the F1-optimal cutoff for your calls, or, better yet, some cost-weighted utility function (which I mention below).
A closer look at ASR confidence
Threshold recalibration restores the Pareto frontier but it turns out ASR confidence has issues that go a bit deeper than our quick-fix. So before reaching for a better calibration trick, it’s worth asking: what is this number actually measuring, why does its meaning slide around, and where does it fall short?
What does ASR confidence mean, really?
Whisper is an autoregressive encoder–decoder Transformer. The encoder turns the audio’s log-mel spectrogram (a picture of how much energy sits in each pitch band over time, scaled to roughly match how human ears hear) into a latent sequence. The decoder is a language model that outputs text tokens one at a time, each conditioned on (a) the audio, via cross-attention, and (b) the tokens it’s already emitted, via causal self-attention. At every step it produces a softmax (a vector of probabilities that sums to 1) over the entire ~51.9k-token byte-pair-encoded vocabulary and picks one. So it’s really next-token prediction, like an LLM, except the difference from a text-only LLM is the extra cross-attention into the audio.
And exp(avg_logprob) is literally the geometric mean of those per-step probabilities: avg_logprob is the mean of log P(chosen token) over the emitted tokens, so exp(avg_logprob) is the typical probability the decoder assigned to each word it committed to. Another way of putting this is it’s just inverse perplexity, where perplexity is exp(−avg_logprob), the standard measure of how surprised a language model is by a string. So high confidence means the model concentrated mass on what it emitted at each step (decisive) and low confidence means it spread its bets. It measures decisiveness, not just fidelity to the audio.4
To make sure we’re clear on the setup here the following is the classic sequence-of-next-token-predictions pic you’ve seen from LLM explainers. But here it’s whisper-tiny.en decoding a spoken ID one token at a time on clean audio (top) and on severe audio (bottom). Each panel is the model’s probability distribution over the next token, top five candidates. The colored bar is the token it actually committed.5
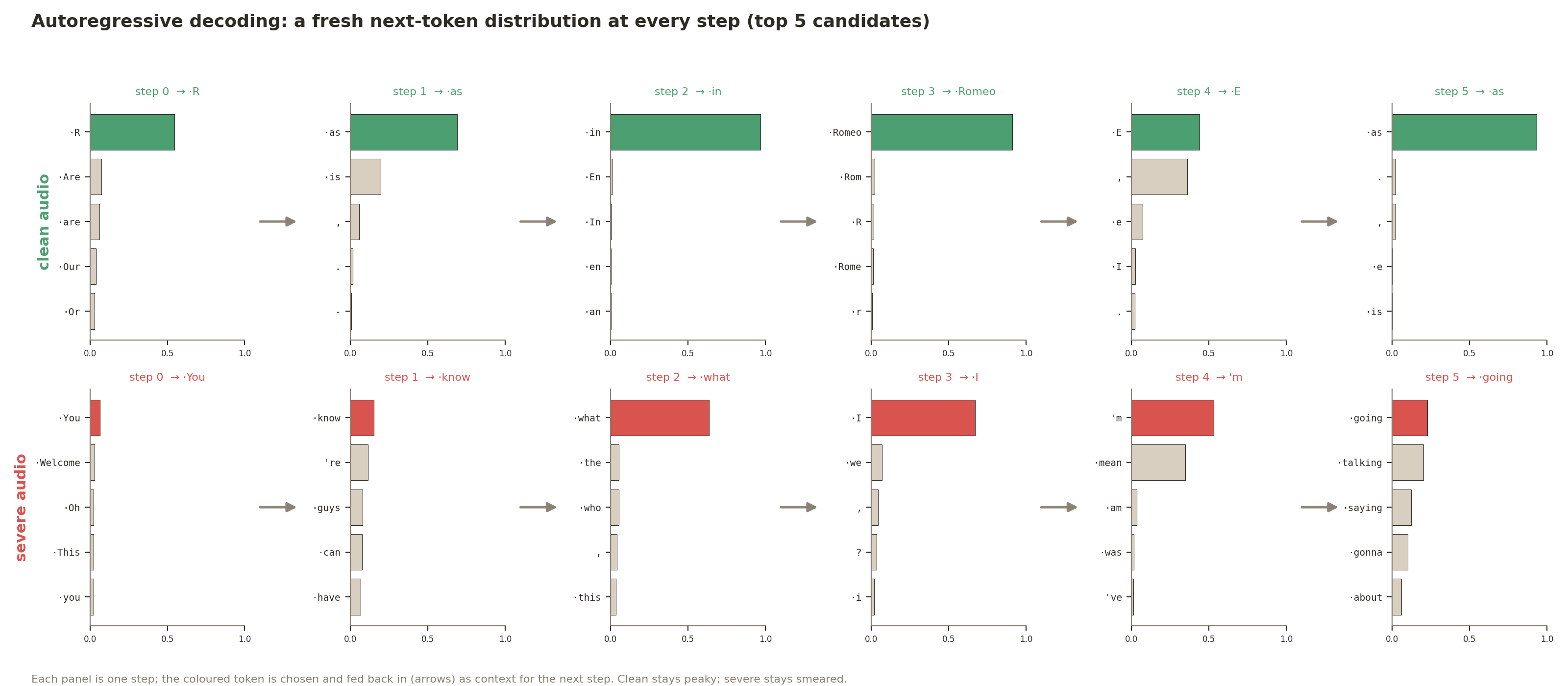
On the clean line the distribution collapses onto one token at every step — R → as → in → Romeo → …, each a near-certain spike, which is exactly what a confidence near 1.0 looks like up close. On the severe line the same model is guessing: the very first token splits its mass across You / Welcome / Oh / This / you, nothing above a few percent. But watch what happens after it commits to “You”: the later steps sharpen right back up (“know what I’m going to…”). My strong hypothesis for what’s happening here is that once a fluent English sentence is underway it’s easy to continue as language, regardless of whether it matches the audio. The confidence partially recovers, but on a hallucination.
So indeed to recap, exp(avg_logprob) measures how sure the decoder was about the tokens it emitted, not whether those tokens are correct. To get a sense for how those two things drift apart we need to measure the correctness of the model’s token predictions more granularly.
Character Error Rate as a proxy for per-token correctness
To ask whether confidence tracks correctness, plain “right vs. wrong” ID capture is too blunt because dropping one digit and inventing a whole sentence are both “wrong,” but they’re not the same failure. Character error rate (CER) is a decent proxy for what we’re after:
CER = levenshtein(reference, transcript) / length(reference)where the Levenshtein (edit) distance is the minimum number of single-character insertions, deletions, or substitutions to turn one string into the other.
Here are two worked examples, both against the same spoken reference “S as in sierra, X-ray, 1, 1, 8, 5”, which normalizes to sasinsierraxray1185 (19 characters):
- One-character slip. Whisper returns “S is in Sierra, X-ray, 118.5.” →
sisinsierraxray1185. A single substitution (theaof “as” → theiof “is”), so CER = 1 / 19 ≈ 0.05. Barely wrong. - Wild hallucination. Whisper returns “Hello, welcome to this channel.” →
hellowelcometothischannel(25 characters). It shares almost nothing with the reference, so it takes 24 edits to rewrite one into the other: CER = 24 / 19 ≈ 1.3 — and it climbs higher the longer the hallucination runs (up to ≈4× across this benchmark).6
When confidence diverges from correctness
Okay, having established how we got the CER values, let’s compare them to ASR confidence for each test case. The following dot plot shows every transcription with the model’s confidence on the x-axis and the CER on the y-axis. This gives us some clearer intuition for how ASR confidence corresponds to correctness. You can hover on dots to see the transcript and click to listen.
Confidence behaves differently on unrecoverable vs recoverable audio
You can see these two regimes (severe vs non-severe) disentangled in the two mini-graphs above. In the non-severe audio graph (right), ASR confidence is a pretty good predictor of correctness. Lower confidence dots here mostly correspond to the model mis-transcribing a few characters. In the severely distorted cases (left), all models are wrong 100% of the time, sometimes hallucinating transcriptions, and other times getting the occasional correct character.
Confidence behaves differently for different model sizes
This whole post was kicked off by the observation that larger Whisper models have overall higher confidence (remember the regression we caught?). But the changes in ASR confidence between models is more nuanced than just “bigger model -> more confident”.
The hypothesis that “bigger models just believe their hallucinations more” turns out to be wrong on severe audio. Whisper-large is not really surer of its hallucinations than the small models. Its median confidence on hallucinations is 0.45, right in the same 0.40–0.47 band as everyone else. So Large is not more deluded about its hallucinations.
What actually shifts is confidence on garbled transcriptions where the model gets a few correct characters. Large produces far more of them (20 of its 39 severe transcripts, versus zero for tiny), and they are more confident than the hallucinations: a median 0.62 for large’s garbled transcriptions against 0.45 for its hallucinations. A likely reason why they are more confident is because they are partly correct: large’s garbled transcriptions have a median raw CER of 1.1, while its hallucinations have a median of 3.3. Tellingly, large is the only model whose confidence meaningfully correlates with error on severe audio (ρ = −0.54, the strongest of the four). Within its own outputs, the surer ones really are less wrong. So Large’s enhanced ability to partially recover severely distorted audio is a characteristic that is not shared by the smaller models.
Going beyond ASR confidence (there’s a simple fix here)
Firstly, it’s clear from the confidence vs CER graph that no amount of threshold calibration is going to produce a perfect classifier. In short, if your voice agent needs to transcribe critical info over possibly distorted audio channels, then ASR confidence is probably not a complete solution to inform your escalation policy. This is a good example of a situation where looking at the data really suggests some strong next steps, which might differ from the default approach.
Namely, a standard tool for classifier calibration is to do something like temperature scaling or isotonic regression, which can turn a raw score into a better-calibrated probability of correctness. One could surely go deep in the technical weeds here but more robust calibration can’t ultimately rescue you when the underlying signal lacks further separating power.
Now take a step back for a second. Are you thinking about the extremely simple (and maybe obvious) major improvement that would resolve most of our wrong commits? Let your LLM make some common sense decisions! The LLM will know from the conversation context what sort of value it should expect. If it’s expecting to hear a medication name or an ID number etc., and instead hears a hallucinated sentence, then it can reason that there’s been a mistake. So boom. That knocks out quite a few wrong commits right there. Additionally, if you look at the data, a number of the most confident wrong commits were actually on the non-severe audio in which the ASR would make contextually apparent mistakes, e.g. transcribing ‘U as in Uniform’ as ‘U.S. in Uniform’. The LLM could catch that as well (though perhaps you’d want to update your system prompt after observing that failure mode).
Beyond the simple win of just using the LLM as a second layer of common sense quality control, some additional simple improvements are to validate against the real world if that’s an option. For example can you check an ID value against a database, and/or are there some formatting or checksum rules it might violate? Thirdly, the LLM can check whether an ID repeated a second time matches what it heard the first time.
A final consideration is that we need to be mindful of what we’re optimizing for. What’s your utility function? Probably not F1. We need to optimize the precision/recall tradeoff for the real world context of the task. What is the cost of a wrong commit versus the cost of an extra human review? The escalation threshold needs to reflect the (possibly) asymmetric cost of wrong commits.
Reflections
If you don’t know where you are going, you might wind up someplace else.
— Yogi Berra
Whether in life or in evals, it pays to be clear on what you want.
When I built the benchmark, I didn’t predict the model-swap miscalibration bug. Indeed if I were building a real agent, the added complexity would surely create opportunities for numerous other bugs. The lesson here is certainly not “remember to calibrate parameters when you swap models”, nor is it even, “design systems that calibrate themselves so you can set it and forget it”. The lesson is that we often can’t predict the problems that will arise. We should therefore get specific about what we care about, and how we’ll know whether our agent is sufficiently aligned in the dimensions we care about (ideally) before we release it into the wild.7
By being clear on the product-level implications of different failure modes, we can specify what it means for our agent to be shippable. In the case of my benchmark, one presumably really cares not just about transcription accuracy but also about generally preventing wrong transcription. It’s good to be clear about that from the start so whatever unexpected bugs arise will be surfaced by your evals in the dimensions you care about.
More concretely, we’ve seen that ASR confidence can be an unreliable predictor of transcription correctness. It changes unevenly per model and behaves especially weirdly on unrecoverable audio. By looking at the data and considering how Whisper comes up with its confidence metric, we got insight into how our heuristic diverges from reality. And instead of just throwing the kitchen sink of common techniques at the problem, we were able to propose a more apt solution based on the failure modes we observed.
drop me a line
I’m the founding engineer at MakeTimeFlow building production AI agents and going deeper on voice-agent evaluation. If you work on voice agents, eval methodology, or anything in this neighborhood, say howdy 👋
Footnotes
-
that is, , the exponentiated arithmetic mean of log-probabilities, which equals the geometric mean of the raw probabilities . Whisper exposes this directly as
avg_logprobin its segment output; puts it back on the scale. ↩ -
Indeed the distortion is both phone-y and phony. The audio pipeline mimics artifacts that sound kind of like that which you’d hear on a phone call, but it’s artificial and doesn’t quite match what you’d really get (e.g. codec hops, background conversations, side speech, bad pronunciation). We assume that our phony distortion pipeline is a decent proxy for the phone-y distortion you’d get in the wild. ↩
-
A lot of voice agents these days still use the modular ASR → LLM → TTS architecture, though surely multimodal models stand a good chance of replacing that stack. Anyway, the benchmark itself doesn’t need to know how an agent decides whether to escalate. It feeds audio samples and grades the agent on its behavior. ↩
-
Multiplying per-token probabilities together isn’t an independence assumption. By the chain rule, exactly. And the decoder parameterizes precisely those conditionals, so the product is the true joint probability of the sequence. That conditioning is also one way a wrong transcript can stay confident: because each token is conditioned on the ones already emitted the later factors can stay high just because the sentence is fluent English. ↩
-
The decoding shown in this figure is greedy: take the single most-probable token at each step. The benchmark itself used beam search, which keeps several candidate sentences alive at once and returns the highest-probability complete one. ↩
-
Because the denominator in our CER metric is the full spelled-out read-back (e.g.
R as in romeo, E as in echo, …which normalizes to ~50 characters), a hallucination that is shorter than that read-back can score below 1.0. A whisper-medium clip on severe returned “Thank you for watching and see you next time” against an 11-character ID and landed at CER 0.83. So it was fully wrong, but the long reference in the denominator pulls the ratio under 1.0. Scored against the bare ID instead, that same clip is 3.6. So the CER is reliable for ranking how wrong things are, but its absolute scale is compressed. ↩ -
This of course is a very small, practical, and near-term version of the far grander and more serious AI alignment problem. It is, however, categorically different, in that long-horizon alignment of super-intelligent AI raises some pretty deep and open questions for science and philosophy, while what we’re talking about here is much more of a tractable and grounded matter: specifying what you want from the country of geniuses in the datacenter is way harder than specifying what you want from your call center customer support agent. ↩